






想了解C++性能优化,有没有比较新的资料(书籍、博客、...)?
book.easyperf.net/perf_book免费的
世面上将c++性能优化的书其实不少了,但是很多都停留在架构、算法、数据结构层面,大都是些老生常谈了。而从语言本身、操作系统、硬件层面系统阐述性能优化的技术书则少了很多。而《optimizing software in c++》正是这样的一本书,作者Agner Fog的职业也挺有意思,除了是计算机科学家,还是进化人类学家,而且后者看起来还是主业..
这周末花了一天时间阅读了这本书中感兴趣的几个章节。笔者将会连载几篇读书笔记总结主要知识点。
- 7 The efficiency of different C++ constructs
- 8 Optimizations in the compiler
- 9 Optimizing memory access
- 11 Out of order execution
- 12 Using vector operations
这章主要介绍c++语言中各种特性对性能的影响。
众所周知,函数中的临时变量或对象一般存储在内存空间中的stack区。每当调用函数时,参数和临时变量进栈,当函数返回时,参数和临时变量出。s由于stack可被不断重复使用,栈是内存空间中最高效的存储方式。当临时变量中没有大对象时,访问栈上的临时变量也基本能用上L1 data cache.
在函数体之外声明的变量称之为global变量,可被任何函数访问。被static修饰的变量称为static变量。
global和static变量在程序运行期间会被放置于内存空间中的静态数据区。静态数据区域分为三个部分:一部分存储const类型的global/static变量,一部分存储已被初始化的global/static变量,最后一部分存储未被初始化的global/static变量
使用静态数据区的好处是,global/static变量在程序启动前就有专门的存储位置,坏处是在程序的生命周期内,这些存储位置将被一直占据,可能会降低data cache的效率。
所以建议尽量不要使用global变量
register变量存储在cpu寄存器中,函数中的临时变量特别适合放到register中。优点很明显,访问register变量比访问RAM快得多,但是cpu寄存器大小是非常有限的,在64位x86架构中,有:
- 14个整数寄存器
- 16个浮点寄存器
volatile用于声明一个变量可被其他线程改变,阻止编译器依赖变量始终具有代码中先前分配的值的假设来进行优化 。
volatile int seconds; // incremented every second by another thread
void DelayFiveSeconds()
{
seconds=0;
while (seconds < 5)
{
// do nothing while seconds count to 5
}
}
上面的代码如果不声明为volatile, 编译器将任务while条件一直成立,即使别的线程中改变了seconds的值。
大多数编译器可以使用关键字 __thread 或 __declspec(thread) 来实现静态变量和全局变量的线程本地存储。这样的变
量对于每个线程都有一个实例 。
线程本地存储是低效的,因为它是通过存储在线程访问块中的指针进行访问的。因此建议尽量避免线程本地存储,代之以stack存储。
c++中通过new/malloc动态分配存储,通过delete/free释放动态分配的的存储,动态分配的存储放在内存空间的heap区中。
优点:使用相对stack存储更加灵活
缺点:动态分配和释放很耗时,容易出现野指针、悬垂指针、内存泄露、内存碎片等问题。
类中声明的变量按照在类中的顺序存储,存储位置由类的对象在哪里定义的决定。static修饰的类成员变量将存储在静态数据区,只有一个实例。
将变量存储在类中的好处是保证了空间局部性,对cpu data cache更友好
对于不同的平台,不同整数类型(char/short/int/long)的大小可能不同。
无论大小如何,整数运算基本都很快,除非使用了大于cpu寄存器大小的类型,比如在32位系统中使用64位整数。
建议在与大小无关且没有溢出风险的情况下使用默认整数大小,例如简单变量、循环计数器等。 在大型数组中,为了更好地
使用数据缓存,最好使用对于特定用途来说足够大的最小整数大小。
在大多数情况下,使用有符号整数和无符号整数在速度上没有区别。 除了
- 除以常数:当你将一个整数除以一个常数时,无符号要快于有符号
- 对于大多数指令集,有符号整数比无符号整数转换成浮点数要快
- 有符号变量和无符号变量的溢出行为不同。
整数运算非常快。加减和位操作只需一个时钟周期,乘法需要3-4个时钟周期,除法需要40-80个。
当仅用于递增整数变量时,使用递增前或递增后都没有区别。效果完全相同。例如,for (i=0; i<n; i++)和for (i=0; i<n; ++i)是一样的。但是当使用表达式的结果时,效率可能会有所不同。例如,x=array[i++]比 x=array[++i]速度更快,因为在后一种情况下,数组元素的地址的计算必须等待 i 的新值,这将使 x 的可用性延迟大约两个时钟周期。
x86架构中有两种浮点计算方法。
- 原始方法:使用8个浮点寄存器组成寄存器栈(长双精度80位)。优点:精度高,不同精度之间无需额外转换,有浮点计算指令可用;缺点:难以生成寄存器变量,浮点计算较慢,整数和浮点数之间转换效率很低
- 向量方法:使用8个或16个向量寄存器(XMM或YMM), 优点:可并行计算,寄存器变量容易实现;缺点:不支持长双精度,数学函数必须使用函数库(但通常比硬件指令更快)
XMM向量寄存器在x86 64架构中可用。如果处理器和操作系统支持AVX指令集,则可使用YMM向量寄存器。当XMM可用时,编译器一般用向量方法计算浮点数
根据微处理器的不同,浮点加法需要3 ‐ 6个时钟周期。乘法需要 4 ‐ 8 个时钟周期。除法需要 14 ‐ 45 个时钟周期
枚举只是隐藏的整数。
短路逻辑:当&&的左操作数为false时,便不会计算右操作数。同理, ||的做操作数为true时,也不会计算右操作数。因此建议将通常为true的操作数放在&&表达式最后,或||表达式的开头。
由于所有以布尔变量作为输入的运算符都要检查输入是否有除0或1之外的值,因此布尔变量会被过度检查。如果知道
操作数除了 0 就是 1,布尔运算可以变得有效率的多。编译器之所以不这样假设,是因为如果变量是没有被初始化的或者是
来自其它未知来源的。
一个整数可被当做布尔向量操作。例如bitmap
指针和引用的效率是一样的,因为它们实际上做的事情是相同的,区别在于编程风格。
指针的优点:功能上更灵活,可以做指针计算(例如访问缓冲区),当然也更容易出错
引用的优点:语法更简单,也更安全。
最重要的是,需要一个额外的寄存器来保存指针或引用的值,而寄存器是一种稀缺资源,如果没有足够的寄存器,那么指针每次使用时都必须从内存中加载,这会使程序变慢。另一个缺点是指针的值需要几个时钟周期才能访问所指向的变量。也就是说,要读取指针或引用的值,最坏情况下需要访问两次内存。
通过函数指针调用函数通常要比直接调用函数多花几个时钟周期 。
在简单的情况下,数据成员指针只是存储数据成员相对于对象开头的偏移量,而成员函数指针只是成员函数的地址。
使用智能指针的目的是为了确保对象被正确删除,以及在对象不再使用时释放内存 。
通过智能指针访问对象没有额外的成本。 但是,每当创建、删除、复制或从一个函数转移到另一个函数时,都会产生额外的成本。shared_ptr 的这些成本要高于 unique_ptr。
数组是通过在内存中连续存储元素来实现的,没有存储关于数组大小的信息。因此c/c++中数组相比其他语言更快,但也更不安全。
应该按顺序访问多维数组,保证最后一个索引变化最快;当不按顺序索引时,为了使地址的计算更高效,那么除了第一个维度外,所有维度的大小最好是 2 的幂。如果以非顺序访问元素,则对象的大小(以字节为单位)最好为 2 的幂。上述建议是为了更好利用cpu的data cache
寄存器值不变,只是编译器换了解释方法。因此没有额外的性能成本。
类型大小转换通常不需要额外的时间
当使用浮点寄存器时,浮点、双精度和长双精度之间的转换不需要额外的时间
当用XMM寄存器时,需要 2 到 15个时钟周期(取决于处理器)
因此建议使用向量化时,不要混用浮点类型。
将有符号整数转换为浮点数或双精度浮点数需要 4 ‐ 16个时钟周期,这取决于处理器和使用的寄存器类型。无符号整数的转
换需要更长的时间。如果没有溢出的风险,首先将无符号整数转换为有符号整数会更快:
如果不启用SSE2 或者更新的指令集,浮点数到整数的转换将花费很长的时间。通常,转换需要 50 ‐ 100 个时钟周期
解决方案:避免转化;使用 64位模式或启用SSE2 指令集;使用四舍五入代替截断,并用汇编语言制作一个舍入函数
指针可以转换为另一种类型的指针。同样,可以将指针转换为整数,也可以将整数转换为指针。值还是那些值,只是换了种解释方法,因此没有任何开销。
其实就是c++中的reinterpret_cast , 没有任何额外开销
const_cast 运算符用于解除 const 对指针的限制 。同上
static_cast 运算符的作用与 C 风格的类型转换相同。例如,它用于将 float 转换为 int
同重新解释对象
ynamic_cast 运算符用于将指向一个类的指针转换为指向另一个类的指针。它在运行时检查转换是否有效 。dynamic_cast比static_cast更耗时,也更安全。
只有当程序员定义了构造函数、重载赋值运算符或重载类型转换运算符(指定如何进行转换)时,才有可能进行涉及类对象
(而不是指向对象的指针)的转换。构造函数或重载运算符与成员函数的效率是一样的
在微处理器做出正确分支预测的情况下,执行分支指令通常需要 0 ‐ 2 个时钟周期。根据处理器的不同,从分支错误预测中恢复
所需的时间大约为 12 ‐ 25 个时钟周期。这被称为分支预测错误的惩罚
for 循环或 while 循环也是一种分支。在每次迭代之后,它决定是重复还是退出循环。嵌套循环只能在某些处
理器上得到很好的预测。在许多处理器上,包含多个分支的循环并不能很好地被预测
switch 语句也是一种分支,它可以有两个以上的分支。如果 case 标签是遵循每个标签等于前一个标签加 1 的序列,在这
个时候 switch语句的效率是最高的,因为它可以被实现为一个目标跳转表。如果 switch 语带有许多标签值,并且彼此相
差较大,这将是低效的,因为编译器必须将其转换成一个分支树
分支和 switch 语句的数量最好在程序的关键部分控制在较少的水平 。因为分支和函数调用的目标保存在称为分支目标缓冲区的特殊缓存中。如果一个程序中有许多分支或函数调用,那么在分支目标缓冲区中就可能产生竞争。这种竞争的结果是,即使分支具有良好的可预测性,它们也可能被错误地预测
https://www.agner.org/optimize/optimizing_cpp.pdf
本文使用 文章同步助手 同步
推荐Agner Fog的5本优化手册:
1. Optimizing software in C++: An optimization guide for Windows, Linux and Мас platforms
2. Optimizing subroutines in assembly language: An optimization guide for x86 platforms
3. The microarchitecture of Intel, AMD and VIA CPUs: An optimization guide for assembly
programmers and compiler makers
4. Instruction tables: Lists of instruction latencies, throughputs and micro-operation
breakdowns for Intel, AMD and VIA CPUs
5. Calling conventions for different C++ compilers and operating systems
Software optimization resources. C++ and assembly. Windows, Linux, BSD, Mac OS X。
来源:https://www.zhihu.com/question/27371815 作者:Milo Yip
推荐阅读书单
正如侯捷老师所说C++ 相关的书籍也非常多,如天上繁星。 广博如四库全书者有 《The C++Programming Language》 《C++ Primer》,深奥如山重水复者有《The Annotated C++ Reference Manual》、《Inside The C++ Object Model》,细说历史者有《The Design And Evolution Of C++》、《Rumiations on C++》,独沽一味者有《Polymorphism in C++》、《Genericity in C++》,独树一帜者有《Design Patterns》、《C++ FAQs》,程序库大全有之《The C++ Standard Library》.....
至于书单的话,可以看下这个C++ 最全书单,包含几十本经典的PDF和下载方式:
大厂15万字C++开发面试手册出炉(C++和计算机基础全有)(PS:侯捷 C++ 视频课程一直都被看过的同学广为推荐,最近发现 B 站关于侯捷老师的 C++ 视频课程几乎全部被下架了,于是自己搜集了一套非常全的视频,大家赶紧去下载保存备用
侯捷C++全套视频|含下载方式?mp.weixin.qq.com/s?__biz=MzU4MjgwNjQ0OQ==&mid=2247486987&idx=1&sn=6002f1b0c275f97a33ee2e3e8f53ab4f&chksm=fdb3f0d5cac479c3368acf8cecbf5b0669ff76db88b3f32d3543fcd8f0f5c820845102493c16#rd?mp.weixin.qq.com/s?__biz=MzU4MjgwNjQ0OQ==&mid=2247486987&idx=1&sn=6002f1b0c275f97a33ee2e3e8f53ab4f&chksm=fdb3f0d5cac479c3368acf8cecbf5b0669ff76db88b3f32d3543fcd8f0f5c820845102493c16#rd?mp.weixin.qq.com/s?__biz=MzU4MjgwNjQ0OQ==&mid=2247486987&idx=1&sn=6002f1b0c275f97a33ee2e3e8f53ab4f&chksm=fdb3f0d5cac479c3368acf8cecbf5b0669ff76db88b3f32d3543fcd8f0f5c820845102493c16#rd?mp.weixin.qq.com/s?__biz=MzU4MjgwNjQ0OQ==&mid=2247486987&idx=1&sn=6002f1b0c275f97a33ee2e3e8f53ab4f&chksm=fdb3f0d5cac479c3368acf8cecbf5b0669ff76db88b3f32d3543fcd8f0f5c820845102493c16#rd他们让知识的传播变得更加的便捷,降低了后来者的学习门槛,当然啦也变相加重了内卷化.
最后给大家介绍一份计算机经典书籍,送大家一份硬核书籍资源:读大学跟工作期间,我买了很多书,大部分是一些技术书籍,也收集了这些书籍的电子版,都在这里,现在免费share给大家,包括了计算机类常用电子书,包括C,C++,Java,Python,Java,Linux,Go等,希望大家能认真阅读。点击下方链接直达获取:
计算机经典必读书单(含下载方式)码字不易,硬核码字更难,希望大家不要吝啬自己的鼓励,给我 :
一个点赞,鼓励下我!

- 1.整数运算效率高于浮点
- 2.除法和取余
- 4.通过2的幂次进行除法和取余数
- 5.使用数组下标
- 6.全局变量->局部变量
- 7.指针值不改变的->拷贝到局部变量
- 8.变量类型
- 9.局部变量
- 10.指针
- 11.指针链
- 12.条件执行
- 13.布尔表达式和范围检查
- 14.布尔表达式和零值比较
- 15.懒检测开发
- 16.用switch()函数替代if…else…
- 17.二分中断
- 18.switch语句vs查找表
代码优化就是找出程序运行缓慢或消耗内存较大的地方。
有的地方需要以空间换时间,有的地方可以以时间节约空间,需要根据不同平台,不同算法,不同场景做出不同选择,才能保证代码运行更快。
程序内部被频繁调用的方法、内部循环嵌套比较深的地方、递归层次较深、遍历大量数据、调用第三方库的地方最应该优化。
最近看到一篇挺好的优化文章,和大家一起分享。本篇文章均来自于《C/C++语言代码优化的经验与方法》见文后Reference。
整形的运算速度高浮点型,可以被处理器直接完成运算,不需要借助于FPU(浮点运算单元)或者浮点型运算库。
这就是很多嵌入式开发都会使用定点数替代浮点数的原因,定点数再用相关整数表示进行计算,就是为了加快运算速率。
如果确定整数非负,就使用效率更高的 unsigned int而不是int,无符号unsigned的除法使用更少的计算机指令。
所以,在一个紧密循环中,声明一个int整形变量的最好方法是:
register unsigned int variable_randy;
浮点数可以先将小数点右移转换为整数,运算完后在转换为小数。
在标准处理器中,一个32位的除法需要使用20至140次循环操作。
对于ARM处理器,有的版本需要20+4.3N次循环。
因此,可以通过乘法表达式来替代除法:
- 比如循环里面需要一直除以一个数,可以在循环外先求出这个数的倒数,然后带入到循环内通过乘法计算
- 如果知道被除数的和除数的符号,判断
,如果a,b为正,可以转换为
如果除法中的除数是2的幂次,编译器会使用移位操作来执行除法。
有符号signed的除法需要移位到0和负数,因此需要更多的时间执行。
当需要根据某个数字来确定某个字符时,可能会这么写:
switch ( randy )
{
case 0 : sesame = 'Q';
break;
case 1 : sesame = 'C;
break;
case 2 : sesame = 'J';
break;
}
// or
if ( randy == 0 )
sesame = 'Q';
else if ( randy == 1 )
sesame = 'C';
else sesame = 'J';
使用数组下标获取字符数组的值就更快捷
static char *types="QCJ";
sesame = types[randy];
全局变量绝不会位于寄存器中,使用全局变量时便需要额外的读取和存储。
建议做法是拷贝全局变量到局部变量,这样可以存放在寄存器。这种方法仅仅适用于全局变量不会被我们调用的任意函数使用。例子如下:
int randy(void);
int sesame(void);
int g_num;
void func1(void)
{
g_num += randy();
g_num += sesame();
}
// 转变 func1 为 func2
void func2(void)
{
int local_num = g_num; // 只加载1次全局变量
local_num += randy();
local_num += sesame();
g_num = localerrs;
}
void randy1( int *input ) {
for(int i=0; i<10; i++) {
sesame( *input, i);
}
}
// randy1 转变为 randy2
void randy2( int *input ) {
int local_input = *input; // 如果 *input 不需要改变,则传递给 local_input
for(int i=0; i<10; i++) {
sesame (local_input, i);
}
}
// 或将 randy 入参设为 const,表示指针不可更改,亦可优化
void randy1(const int *input ) {
for(int i=0; i<10; i++) {
sesame( *input, i);
}
}
基本类型:char、short、int、long(包括有符号signed和无符号unsigned)、float和double。
正确判断所使用的的变量需要什么类型,就赋予什么变量类型。
比如整数,就不要赋予 float 和 double类型; 即使是整形,也有 int8, int16, int 32, int64之分,根据数值范围进行有效选择。
编译器需要在每次赋值char和short类型的时候会将局部变量减少到8位或者16位。
这对于有符号变量称之为有符号扩展,对于无符号变量称之为零扩展。
这些扩展可以通过寄存器左移24或者16位,然后根据有无符号标志右移相同的位数实现,这会消耗两次计算机指令操作(无符号char类型的零扩展仅需要消耗一次计算机指令)。
无论输入输出数据是8位或者16位,将它们考虑为32位是值得的,通过使用int和unsigned int类型的局部变量来避免这样的移位操作。
考虑下面3个函数:
int wordinc (int a)
{
return a + 1;
}
short shortinc (short a)
{
return a + 1;
}
char charinc (char a)
{
return a + 1;
}
结果均相同,第一个程序片段wordinc运行速度高于后两者。
尽可能的使用引用的方式传递结构数据,也就是说使用指针,避免拷贝数据到栈中的过程。
如果确定不改变数据的值,可以将指针指向的内容定义为const 。例如:
void Print_data (const RandyData *data_pointer)
{
...printf contents of the data...
}
指针链经常被用于访问结构数据。例如,常用的代码如下:
typedef struct { int x, y, z; } Point3;
typedef struct { Point3 *pos, *direction; } Position;
void InitPos1(Position *p)
{
p->pos->x = 0;
p->pos->y = 0;
p->pos->z = 0;
}
代码中会重复调用p->pos,可以缓存p->pos到一个局部变量,该局部变量指向p->pos:
void InitPos2(Object *p)
{
Point3 *pos = p->pos;
pos->x = 0;
pos->y = 0;
pos->z = 0;
}
另一种方法是:将Point3类型的数据直接写到在Position结构中,直接访问 x,y,z
typedef struct { int x, y, z; } Point3;
typedef struct { int* x, y, z, int*dx, dy, dz; } Position;
同理,如果需要在循环中访问某个数组成员,可以先将其提取出来再访问
for(int i =0; i < 33; ++i) {
auto pt3 = pts[i];
// do sth with pt3....
}
集中if else中的包含的关系运算符(<,==,>等)判断条件,可以执行更快,并且把最能够有效判断的条件放在最前面,可以加速判断。
int randy(int qa, int qb, int qc, int qd)
{
if (qa > 0 && qb > 0 && qc < 0 && qd < 0)
return a * b + c - d;
return -1;
}
条件聚集到一起,编译器能够集中处理。
经常需要判断变量是否位于某个范围内,例如:
bool PointInRectangelArea (Point p, Rectangle *r)
{
return (p.x >= r->xmin && p.x < r->xmax &&
p.y >= r->ymin && p.y < r->ymax);
}
更快的方法:x>min && x<max可以转换为(unsigned)(x-min)<(max-min)。
这对于min等于0时更为有益。
修改后代码如下:
bool PointInRectangelArea (Point p, Rectangle *r)
{
return ((unsigned) (p.x - r->xmin) < r->xmax &&
(unsigned) (p.y - r->ymin) < r->ymax);
}
这条应与14条相结合修改
处理器的标志位在比较指令操作后被设置。
标志位同样可以被诸如MOV、ADD、AND、MUL等基本算术和裸机指令改写。
如果数据指令设置了标志位,N和Z标志位也将与结果与0比较一样进行设置。
N标志表示结果是否是负值,Z标志表示结果是否是0。
C语言中,处理器中的N和Z标志位与下面的指令联系在一起:
- 有符号关系运算
x<0,x>=0,x==0,x!=0; - 无符号关系运算
x==0,x!=0(或者x>0)。
C代码中每次关系运算符的调用,编译器都会发出一个比较指令。
如果操作符是上面提到的,编译器便会优化掉比较指令。例如:
int Randy(int x, int y)
{
if (x + y < 0)
return 1;
else
return 0;
}
尽可能的使用上面的判断方式,这可以在关键循环中减少比较指令的调用,进而减少代码体积并提高代码性能。
C语言没有借位和溢出位的概念,但编译器支持借位(无符号溢出),例如:
int sum(int x, int y)
{
int res;
res = x + y;
if ((unsigned) res < (unsigned) x) // carry set? //
res++;
return res;
}
在if(randy>13 && sesame=2)这样的语句中,确保 && 表达式的第1部分完成判断或者大部分判断都会在第1部分结束,这样第2部分便不需要执行。
对于涉及if…else…else…多条件判断,例如:
if( randy == 1)
Play1();
else if (randy == 2)
Play2();
else if (randy == 3)
Play3();
使用if else 时,将最可能执行最先判断,这样就能最快跳出if else 判断,不用继续判断;
使用switch可能更快:
switch( randy )
{
case 1: Play1(); break;
case 2: Play2(); break;
case 3: Play3(); break;
}
Switch也是
如果有如下判断,会很头大:
if(a==1) {
} else if(a==2) {
} else if(a==3) {
} else if(a==4) {
} else if(a==5) {
} else if(a==6) {
} else if(a==7) {
} else if(a==8)
PlayRandy();
{
}
使用二分方式替代它,如下:
if(a<=4) {
if(a==1) {
} else if(a==2) {
} else if(a==3) {
} else if(a==4) {
}
}
else
{
if(a==5) {
} else if(a==6) {
} else if(a==7) {
} else if(a==8) {
}
}
或者如下:
if(a<=4)
{
if(a<=2)
{
if(a==1)
{
/* a is 1 */
}
else
{
/* a must be 2 */
}
}
else
{
if(a==3)
{
/* a is 3 */
}
else
{
/* a must be 4 */
}
}
}
else
{
if(a<=6)
{
if(a==5)
{
/* a is 5 */
}
else
{
/* a must be 6 */
}
}
else
{
if(a==7)
{
/* a is 7 */
}
else
{
/* a must be 8 */
}
}
}
背后的逻辑就是在数组中找到目标数字,使用二分肯定更快点。
比较如下两种case语句:
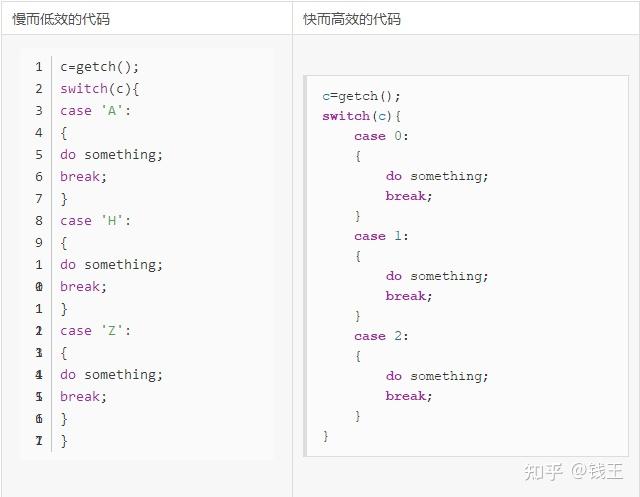
======001
Switch的应用场景如下:
- 调用1到多个函数
- 设置变量值或者返回一个值
- 执行1到多个代码片段
如果case标签很多,在switch的前两个使用场景中,使用查找表可以更高效的完成。例如下面的两种转换字符串的方式:
char * Switch_String1(int condition) {
switch(condition) {
case 0: return "QQ";
case 1: return "CC";
case 2: return "JJ";
case 3: return "RR";
case 4: return "AA";
case 5: return "NN";
case 6: return "DD";
case 7: return "YY";
case 8: return "HI";
case 9: return "LS";
case 10: return "GE";
case 11: return "LT";
case 12: return "GT";
case 13: return "LE";
case 14: return "";
default: return 0;
}
}
const char* Switch_String2(int condition) {
if ((unsigned)condition >= 15) {
return 0;
}
return "QQ\\0CC\\0JJ\\0RR\\0AA\\0NN\\0DD\\0YY\\0HI\\0LS\\0GE\\0LT\\0GT\\0LE\\0\\0" +
3 * condition;
}
第1个程序需要240 bytes,而第2个仅仅需要72 bytes。
第2个程序解释下:返回一个字符指针地址,然后后面的 3 * condition 就是相对于一堆字符串的首地址的偏移位置,因为返回后读取时,读到\\0结束,因此每次取到所需要的2个字符+\\0字符,正好3个字符。
循环终止条件不同会导致额外的负担。应该使用计数到零的循环和简单的循环终止条件。
看下面计算n!的两个程序。第1个递增,第2个递减。
int fact1_randy (int n)
{
int i, fact = 1;
for (i = 1; i <= n; i++)
fact *= i;
return (fact);
}
int fact2_randy(int n)
{
int i, fact = 1;
for (i = n; i != 0; i--) // 或写成 for (i=n; i ; i--)
fact *= i;
return (fact);
}
fact2_randy执行效率更高,因为fact1_randy 中每次需要判断 i - n 的值,然后再和0判断,比直接和0判断多了1步。
能用一个循环解决问题坚决不用二个。下面是一个例子:

======002
调用函数时总是会有一定的性能消耗。
不仅程序指针需要改变,而且使用的变量需要压栈并分配新变量。
如果循环中一个函数经常被调用,那么就将循环纳入到函数中,这样可以减少重复的函数调用。代码如下:
for(i=0 ; i<100 ; i++)
{
randy(t,i);
}
void randy(int w,d)
{
// calculate lots of stuff.
}
应改为:
void randy(w)
{
for(i=0 ; i<100 ; i++)
{
//calculate lots of stuff.
}
}
简单的循环可以展开以获取更好的性能,但需要付出代码体积增加的代价。
如果循环迭代次数只有几次,那么可以完全展开循环,以便消除循坏带来的负担。
循环展开可以带非常可观的节省性能,原因是代码不用每次循环需要检查和增加i的值。例如:

======003
编译器通常会像上面那样展开简单的,迭代次数固定的循环。但是像下面的代码:
for(i=0;i< limit;i++) { ... }
下面的代码(Example 1)明显比使用循环的方式写的更长,但却更有效率。
BLOCKSIZE的值设置为8仅仅适用于测试的目的。
在这个例子中,循环条件每8次迭代才会被检查,而不是每次都进行检查。
因此,尽可能的展开循环可以让我们获得更好的执行速度。
//Example 1
#include
#define BLOCKSIZE (8)
void main(void)
{
int i = 0;
int limit = 33; /* could be anything */
int blocklimit;
/* The limit may not be divisible by BLOCKSIZE,
* go as near as we can first, then tidy up.
*/
blocklimit = (limit / BLOCKSIZE) * BLOCKSIZE;
/* unroll the loop in blocks of 8 */
while( i < blocklimit )
{
printf("process(%d)\
", i);
printf("process(%d)\
", i+1);
printf("process(%d)\
", i+2);
printf("process(%d)\
", i+3);
printf("process(%d)\
", i+4);
printf("process(%d)\
", i+5);
printf("process(%d)\
", i+6);
printf("process(%d)\
", i+7);
/* update the counter */
i += 8;
}
}
通过不断的左移,提取并统计最低位
示例程序2每次判断4位,将4次移位合并成1次。
//Example - 1
int countbit1(uint n)
{
int bits = 0;
while (n != 0)
{
if (n & 1) bits++;
n >>= 1;
}
return bits;
}
//Example - 2
int countbit2(uint n)
{
int bits = 0;
while (n != 0)
{
if (n & 1) bits++;
if (n & 2) bits++;
if (n & 4) bits++;
if (n & 8) bits++;
n >>= 4;
}
return bits;
}
通常,循环并不需要全部都执行。
如果在循环中完成了目的,就应该尽可能早的断开循环。
例如:如下循环从10000个整数中查找是否存在-99。
found = FALSE;
for(i=0; i<10000; i++)
{
if( list[i] == -99 )
{
found = TRUE;
break;
}
}
if( found )
printf("Yes, there is a -99. Randy!\
");
假如待查数据位于第23个位置上,程序便会执行23次,从而节省9977次循环。
当然上述查找可以通过二分法等高效查找法进行。
设计小而简单的函数是个很好的习惯。这允许寄存器可以执行一些诸如寄存器变量申请的优化,是非常高效的。
函数调用对于处理器的性能消耗是很小的,只占有函数执行工作中性能消耗的一小部分。
参数传入函数变量寄存器中有一定的限制。
这些参数必须是整型兼容的(char,shorts,ints和floats都占用一个字)或者小于四个字大小(包括占用2个字的doubles和long longs)。
如果参数限制个数为4,那么第5个和之后的字就会存储在栈上。这便在调用函数是需要从栈上加载参数从而增加存储和读取的消耗。
看下面的代码:
int randy1(int a, int b, int c, int d) {
return a + b + c + d;
}
int q1(void) {
return randy1(1, 2, 3, 4);
}
int randy2(int a, int b, int c, int d, int e, int f) {
return a + b + c + d + e + f;
}
ing q2(void) {
return randy2(1, 2, 3, 4, 5, 6);
}
函数randy2中的第5个和第6个参数存储于栈上并在函数q2中进行加载,会多消耗2个参数的存储。
减少函数参数传递消耗的方法有:
- 尽量保证函数使用少于四个参数。这样就不会使用栈来存储参数值。
- 如果函数需要多于四个的参数,尽量确保使用后面参数的价值高于让其存储于栈所付出的代价。建议将参数放入一个结构体并通过指针传入函数,可以减少参数的数量并提高可读性。
- 通过指针传递参数的引用而不是传递参数结构体本身。
- 尽量少用占用2个字大小的参数。如long类型,对于需要浮点类型的程序,double也因为占用两个字大小而应尽量少用。
- 避免函数参数既存在于寄存器又存在于栈中(称之为参数拆分)。现在的编译器对这种情况处理的不够高效:所有的寄存器变量也会放入到栈中。
- 避免变参。变参函数将参数全部放入栈。
不调用任何函数的函数称之为叶子函数。
由于不需要执行寄存器变量的存储和读取,叶子函数在任何平台都很高效。
寄存器变量读取的性能消耗,相比于使用四五个寄存器变量的叶子函数所做的工作带来的系能消耗是非常小的。所以尽可能的将经常调用的函数写成叶子函数。
函数调用的次数可以通过一些工具检查。下面是一些将一个函数编译为叶子函数的方法:
- 避免调用其他函数:包括那些转而调用C库的函数(比如除法或者浮点数操作函数)。
- 对于简短的函数使用__inline修饰()。
内联函数禁用所有的编译选项。使用__inline修饰函数导致函数在调用处直接替换为函数体。这样代码调用函数更快,但增加代码的大小,特别在函数本身比较大而且经常调用的情况下。
__inline int square(int x) {
return x * x;
}
#include
double length(int x, int y){
return sqrt(square(x) + square(y));
}
使用内联函数的好处如下:
- 没有函数调用负担。函数调用处直接替换为函数体,因此没有诸如读取寄存器变量等性能消耗。
- 更小的参数传递消耗。由于不需要拷贝变量,传递参数的消耗更小。如果参数是常量,编译器可以提供更好的优化。
内联函数的缺陷是如果调用的地方很多,代码的体积会变得很大。这主要取决于函数本身的大小和调用的次数。
仅对重要的函数使用inline是明智的。如果使用得当,内联函数甚至可以减少代码的体积:函数调用会产生一些计算机指令,但是使用内联的优化版本可能产生更少的计算机指令。
函数通常可以设计成查找表,这样可以显著提升性能。
sin、cos查找表可能更合适,虽然会牺牲一部分精度。
当使用查找表时,尽可能将相似的操作放入查找表,这样比使用多个查找表更快,更能节省存储空间。
浮点运算对于所有的处理器都很耗时。
请记住:
- 浮点除法很慢。。通过使用常量将除法转换为乘法。常量的除法在编译期间计算。
- 使用float代替double。Float类型的变量消耗更好的内存和寄存器,并由于精度低而更加高效。如果精度够用,尽可能使用float。
- 避免使用先验函数。先验函数,例如sin、exp和log是通过一系列的乘法和加法实现的(使用了精度扩展)。这些操作比通常的乘法至少慢十倍。
- 简化浮点运算表达式。编译器并不能将应用于整型操作的优化手段应用于浮点操作。例如,3*(x/3)可以优化为x,而浮点运算就会损失精度。因此,如果知道结果正确,进行必要手工浮点优化是有必要的。
最好的办法或许是使用定点算数运算。当值的范围足够小,定点算数操作比浮点运算更精确、更快速。
通常,可以使用空间换时间。比如sine和cosine查找表,或者伪随机数。
- 尽量不在循环中使用++和–。例如:while(n–-){},这有时难于优化。
- 减少全局变量的使用。除非必须声明为全局变量,使用static修饰变量为文件内访问。
- 尽可能使用一个字大小的变量(int、long等),使用它们(而不是char,short,double,位域等)机器可能运行的更快。
- 不使用递归。递归可能优雅而简单,但需要太多的函数调用。
- 不在循环中使用sqrt开平方函数,计算平方根非常消耗性能。
- 一维数组比多维数组更快。
- 编译器可以在一个文件中进行优化-避免将相关的函数拆分到不同的文件中,如果将它们放在一起,编译器可以更好的处理它们(例如可以使用inline)。
- 单精度函数比双精度更快。
- 浮点乘法运算比浮点除法运算更快-使用val*0.5而不是val/2.0。
- 加法操作比乘法快-使用randy+randy+randy而不是randy*3。
- put()函数比printf()快,但不灵活。
- 使用#define宏取代常用的小函数。
- 二进制/未格式化的文件访问比格式化的文件访问更快,因为程序不需要在人为可读的ASCII和机器可读的二进制之间转化。如果你不需要阅读文件的内容,将它保存为二进制。
- 如果你的库支持mallopt()函数(用于控制malloc),尽量使用它。MAXFAST的设置,对于调用很多次malloc工作的函数由很大的性能提升。如果一个结构一秒钟内需要多次创建并销毁,试着设置mallopt选项。
最后,但是是最重要的是-将编译器优化选项打开!看上去很显而易见,但却经常在产品推出时被忘记。编译器能够在更底层上对代码进行优化,并针对目标处理器执行特定的优化处理。
性能优化涉及 CPU、内存、磁盘、网络等方面,是一个十分广泛的话题,推荐一篇 MegEngine 团队的过往文章,该文章主要解析 Python 及 C/C++ 拓展程序在 CPU 上的性能优化,希望能解答题主的疑问。
文章主要围绕着下面三个问题展开:
- Python 及 C/C++ 拓展程序的常见的优化目标有哪些
- 常见工具的能力范围和局限是什么,给定一个优化目标我们应该如何选择工具
- 各种工具的使用方法和结果的可视化方法
除此之外,本文还会介绍一些性能优化中需要了解的基本概念,并在文章末尾以 MegEngine 开发过程中的一个性能优化的实际案例来展示一个优化的流程。
以下为文章全文:
MegEngine Bot:profiling 与性能优化总结更多 MegEngine 信息获取,您可以:
查看MegEngine 文档和 GitHub 项目,或加入 MegEngine 用户交流 QQ 群:1029741705

