






不管是深度学习还是普通的回归或者分类任务,我们都是在最小化目标损失函数。针对一个优化问题,我们的任务是朝着目标函数损失减小的方向移动。如何对这些参数优化迭代,从而达到这个目的,这就是我们的优化算法需要干的事情。
梯度下降法是可以在一定情况下,可以由泰勒展开推导出来,具体的可参见泰勒展开-梯度下降。
标准的梯度下降就是,给一个数据集,按照整体的梯度的方向优化参数。
标准的梯度下降会存在很大的问题,容易陷在局部最优解,而且运算效率也不高,为了解决这个问题,可以抽取一小批数据,用这一小批的数据来作为梯度做参数更新,整体的数据可以分成多批次。相比标准的梯度下降,训练时间缩短,并且下降的方向都比较正确。
来一个样本,计算一个梯度,并进行一次参数迭代,这就是随机梯度下降。随机梯度下降虽然会导致到达最优点时需要迭代非常多次,由于只需要采样一些点来更新模型参数,大数据集时训练会比较快。SGD在随机梯度时会引入噪声,使得参数更新的方向不一定正确。
以上的三种方式都存在容易落入局部最优解问题。
动量算法在梯度下降的基础上进行改变,具有加速梯度下降的作用,可以理解为给梯度增加一个固定的加速度。
vt表示t时刻积累的加速度,alpha表示动力大小,一般取值为0.9(表示最大速度10倍于SGD)。该策略的含义是,当前参数的改变会收到上一次参数变化的影响,可理解为小球向下滚动时带上了惯性,加速小球向下滚动的速度。
NAG方法只是在Wt的梯度上做了些改变,从直接梯度到使用牛顿迭代方法的梯度计算。
之前这些优化算法的学习率都是固定的,而学习率对于整个算法的性能和效果的影响极大,因此出现了自适应的优化算法。
学习率缩放参数反比于所有梯度历史平均值和的平方根,特点是在最大梯度参数下又个快速下降的学习率,而具有小梯度的参数在学习率上有较小的下降。
- adagrad针对补平衡数据或稀疏数据集比较适用,会给类别出现较多的数据给予越来越小的学习率,对于出现次数教少的类别,学习率会相对较大
- 优点是自动调节学习率,缺点是随着迭代次数增多,学习率越来越小,最终趋于0
修改了adagrad的梯度累积,修改成了指数加权的移动平均,其中alpha一般取0.9,表示动力,
上面的所有算法有需要指定全局的学习率,adadelta不需要指定,同时结合了adagrad和RMSProp两种算法策略,
不需要设置全局的学习率,训练的前期和后期,表现会比较好,训练速度也快,但是后期会在局部最小值附近抖动。
并入了梯度一阶矩(指数加权)的估计,还包括了偏置修正,修正从原点初始化的一阶矩(动量项)和二阶矩(非中心的)。
其中mt和vt分别是一阶动量和二阶动量,beta1和beta2分别取0.9和0.999,mt_hat和vt_hat分别是各自的修正值。
adam通常被认为对超参数的选择相当鲁棒,尽快学习率有时需要从建议的默认值修改。
上述的所有优化算法都是针对批量数据的,在一些场景下,我们的数据只能过一次,而且数据极其稀疏,比如广告ctr和cvr领域。这时,要求我们在过一遍数据的限制下,能够更快的收敛,并且能产生稀疏的解。SGD适用此场景,但很难产生稀疏解。
就是加入L1范数,在此基础上做截断。
将每一个数据的迭代过程,分解成一个经验损失梯度下降迭代和一个最优化问题,是truncated gradient的一种特殊形式。
4.3 RDA算法
能够更好地在精度和稀疏性之间做trade-off
前面几个算法都存在一些问题,所以FTRL结合了这几类算法,能很好的平衡稀疏性和精度。
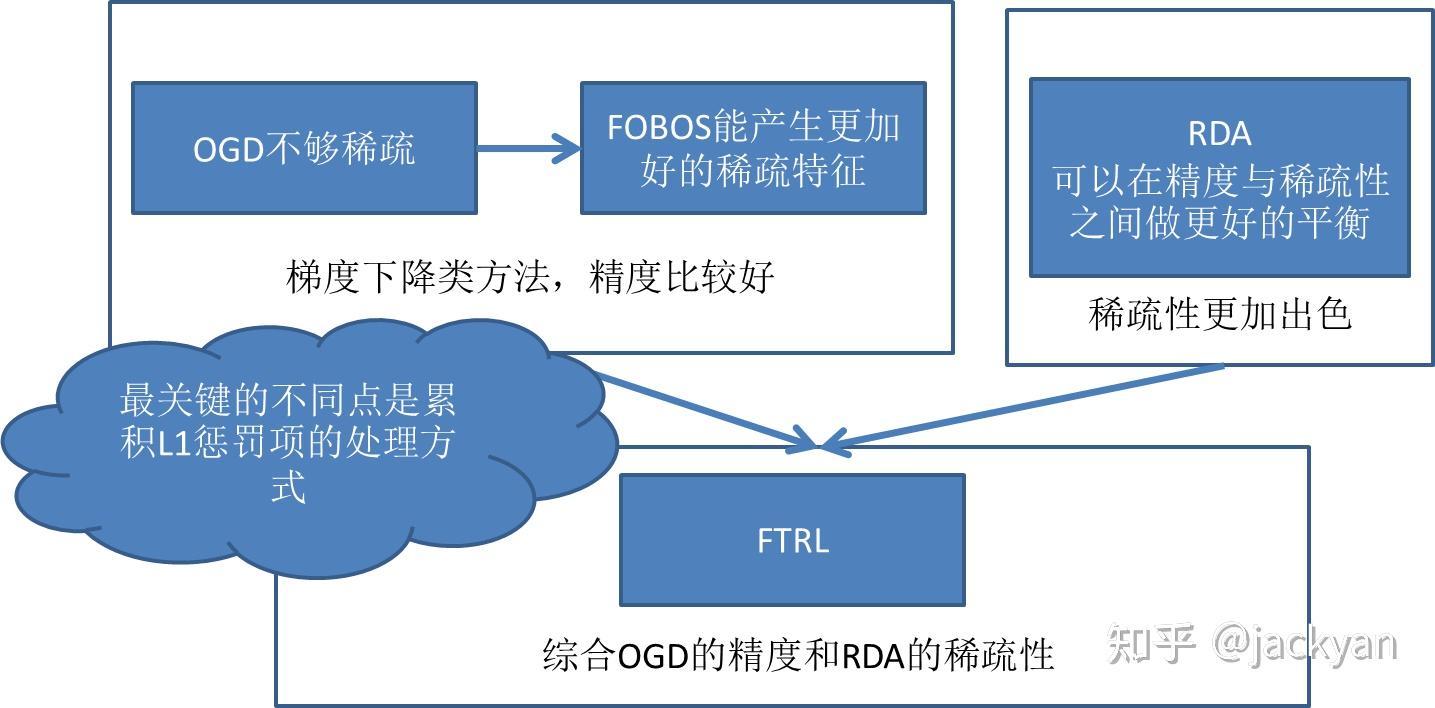
具体的,由于在线学习随机性比较大,所以,g1:t代替了gt, 表示1到t的累积梯度,避免局部抖动太大导致错误判断(Follow the Leader),另外也不希望新更新的w距离上一次的太远,因此加入了正则,
- An overview of gradient descent optimization algorithms
- https://zhuanlan.zhihu.com/p/82757193
- https://www.cnblogs.com/massquantity/p/12693314.html
- Follow-the-regularized-leader and mirror descent: Equivalence theorems and L1 regularization
- https://www.cnblogs.com/EE-NovRain/p/3810737.html

