






全书已翻译完毕:Github repo:https://github.com/realYurkOfGitHub/translation-Introduction-to-HPC
工作在同一个任务上的不同处理器常常需要交流,这需要有一种方法能够帮助其交换数据。本节中我们将讨论一些常见的处理机连接方式,这被称为(处理器)「拓扑」(topology)。
为了明确这里的问题,请考虑两个不能 "扩展 "的简单方案。
- 以太网是一种连接方案,网络上的所有机器都在一条电缆上(见下文注释)。如果一台机器在电线上放了一个信号来发送信息,而另一台机器也想发送信息,那么后者将检测到唯一可用的通信通道被占用,它将等待一段时间后再重新进行发送操作。在以太网上接收数据是很简单的:信息包含了目标接收者的地址,所以一个处理器只需要检查电线上的信号是否是为它准备的。
这个方案的问题应该很清楚。通信通道的容量是有限的,所以当更多的处理器连接到它时,每个处理器可用的容量将下降。由于解决冲突的方案,信息开始前的平均延迟也会增加。 - 在完全连接的配置中,每个处理器都有一条与其他处理器通信的线路。
其他处理器。这种方案是完美的,因为消息可以在最短的时间内发送,而且两个消息永远不会互相干扰。一个处理器可以发送的数据量不再是处理器数量的递减函数;事实上,它是一个递增函数,如果网络控制器可以处理,一个处理器甚至可以同时进行多次通信。
当然,这个方案的问题是,一个处理器的网络接口的设计不再是固定的:随着更多的处理器被添加到并行机器上,网络接口得到更多的连接线。网络控制器也同样变得更加复杂,机器的成本增加速度超过了处理器数量的线性增长。
注释 10 以上对以太网的描述是对原始设计的描述。随着交换机的使用,特别是在HPC的背景下,这种描述已经不再真正适用。
最初人们认为,信息碰撞意味着以太网将不如其他解决方案,如IBM的令牌环网,它明确地防止碰撞。需要相当复杂的统计分析来证明,以太网的工作原理比朴素预期好得多。
在本节中,我们将看到一些可以增加到大量处理器的方案。
互联并行计算机中的处理器的网络可以方便地用一些基本的图论概念来描述。我们用一个图来描述并行机器,每个处理器都是一个节点,如果两个节点之间有直接的联系,那么这两个节点就是相连的。(我们假设连接是对称的,所以网络是一个无向图)
下面分析图的两个重要概念。
首先,图中一个节点的程度是它所连接的其他节点的数量。节点代表处理器,边代表导线,很明显,高度不仅是计算效率所希望的,而且从工程的角度来看也是昂贵的。我们假设所有处理器都有相同的度。
其次,从一个处理器到另一个处理器的信息,通过一个或多个中间节点,很可能在节点之间路径的每个阶段产生一些延迟。由于这个原因,图的直径很重要。直径被定义为任何两个节点之间的最大最短距离,包括链接的数量。
如果 是直径,如果在一条线上发送一个信息需要单位时间,这意味着一个信息总是在最多
时间内到达。
练习 2.30 找出处理器的数量、它们的程度和连接图的直径之间的关系。
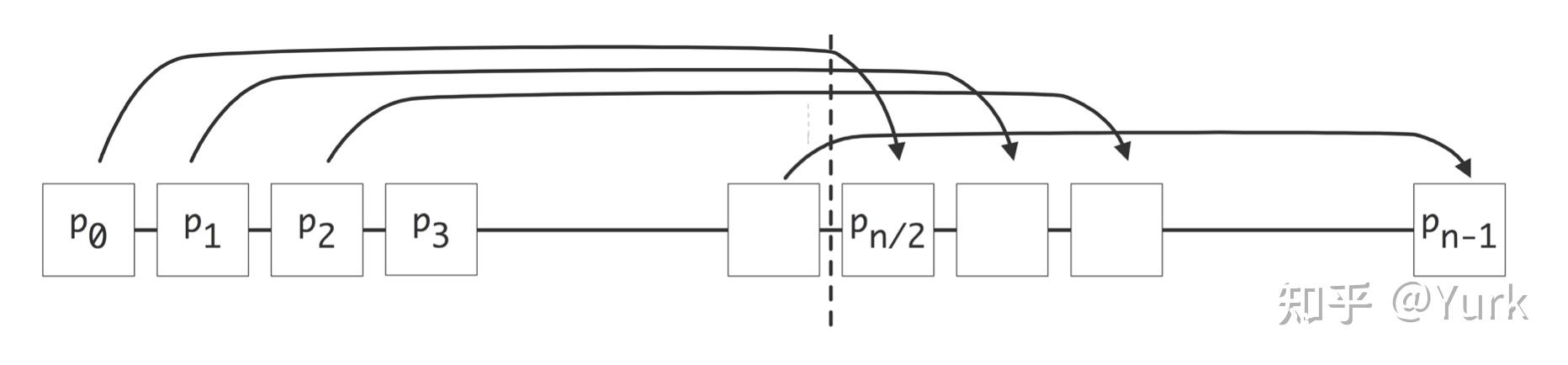
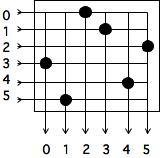
除了 "一个消息从处理器A到处理器B需要多长时间 "的问题外,我们还经常担心两个同时进行的消息之间的冲突:是否存在两个同时进行的消息需要使用同一网络链接的可能性?在图 2.18 中,我们说明了如果每个处理器 在
的情况下向
发送消息会发生什么:会有
的消息试图通过
和
之间的线路。这种冲突被称为「拥堵」(congestion)或「争夺」(contention)。显然,一台并行计算机的链接越多,发生拥堵的机会就越小。
描述拥堵可能性的一个精确方法是看「二分宽度」(bisection width)。这被定义为将处理器图分割成两个非连接图所必须移除的最小链接数。例如,考虑处理器连接成一个线性阵列,即处理器 与
和
连接。在这种情况下,分界线宽度为1。
二分宽度 描述了在一台并行计算机中可以保证有多少信息同时进行。证明:采取
发送和
接收处理器。这样定义的
路径是不相交的:如果不相交,我们只需去除
个链接就可以把处理器分成两组。
当然,在实践中,超过 条信息可以同时进行。例如,在一个线性阵列中,
,如果所有的通信都是在邻居之间,如果一个处理器在任何时候都只能发送或接收,而不能同时发送和接收,则可以同时发送和接收
条信息。如果处理器可以同时发送和接收,那么网络中可以有
个信息正在进行。
二分宽度也描述了网络中的「冗余度」(redundancy):如果一个或多个连接出现故障,信息是否仍能从发送方找到接收方?
虽然二分宽度是一种表示导线数量的措施,但实际上我们关心的是通过导线的容量。这里的相关概念是「二分带宽」(bisection bandwidth):横跨分节宽度的带宽,是分节宽度与导线容量(以每秒比特为单位)的乘积。二分带宽可以被认为是衡量任意一半处理器与另一半处理器进行通信所能达到的带宽。二分带宽是一个比有时引用的总带宽更现实的衡量标准,它被定义为每个处理器都在发送时的总数据率:处理器的数量乘以连接的带宽乘以一个处理器可以执行的同时发送的数量。这可能是一个相当高的数字,而且它通常不能代表实际应用中实现的通信速率。
我们考虑的第一个互连设计是让所有的处理器位于同一内存总线上。这种设计将所有处理器直接连接到同一个内存池,因此它提供了一个UMA或SMP模型。
使用总线的主要缺点是可扩展性有限,因为每次只有一个处理器可以进行内存访问。为了克服这个问题,我们需要假设处理器的速度比内存慢,或者处理器有缓存或其他本地内存来操作。在后一种情况下,通过让处理器监听总线上的所有内存流量,维持缓存一致性是很容易的,这个过程被称为「监听」(snooping)。
连接多个处理器的一个简单方法是将它们连接成一个「线性阵列」(linear array):每个处理器都有一个编号 ,处理器
与
和
相连。第一个和最后一个处理器是可能的例外情况:如果它们相互连接,我们称该架构为环状网络(ring network)。
这个方案要求每个处理器有两个网络连接,所以设计相当简单。
练习2.31 线性阵列的二分宽度是什么?环状网络的二分宽度是什么?
练习2.32 由于线性数组的连接有限,你可能必须对并行算法进行巧妙的编程。例如,考虑一个 "广播 "操作:处理器0有一个数据项需要发送给其他每个处理器。
我们做了以下简化的假设。
- 一个处理器可以同时发送任意数量的信息。
- 但一条线一次只能携带一条信息;然而。
- 任何两个处理器之间的通信都需要单位时间,不管它们之间有多少个处理器。
在一个「全连接」(fully connected)的网络或一个「星型」(star)网络中,你可以很容易地写出:
for = 1 ... ? 1:
send the message to processor 假设一个处理器可以发送多个消息,即操作是一步到位的。现在考虑一个线性阵列。说明即使有这种无限的发送能力,上述算法也会因为拥堵而遇到麻烦。
请你尝试找到一个更好的方法来组织发送操作。提示:假装你的处理器是以二叉树的形式连接的。假设有 个处理器。证明广播可以在
个阶段内完成,并且处理器只需要能够同时发送一条信息即可。
这个练习是一个将 "逻辑 "通信模式嵌入物理模式的例子。
一种流行的并行计算机设计是将处理器组织在一个二维或三维的「笛卡尔网状」(Cartesian mesh)网络中。这意味着每个处理器都有一个坐标 或
,并且它在所有坐标方向上都与邻居相连。处理器的设计还是相当简单的:网络连接的数量(连接图的度数)是网络的空间维数(2或3)的两倍。
拥有二维或三维网络是一个相当自然的想法,因为我们周围的世界是三维的,而且计算机经常被用来模拟现实生活的现象。如果我们暂时接受物理模型需要近邻型通信,那么网状计算机是运行物理模拟的自然候选者。
练习2.33 处理器的三维立方体的直径是多少?二分宽度是多少?如果增加环绕环状的连接,会有什么变化?
练习 2.34 你的并行计算机的处理器被组织成一个二维网格。芯片制造商推出了一种具有相同时钟速度的新芯片,它是双核的,而不是单核的,而且可以装在现有的插槽上。批评以下论点:"每秒钟可以完成的工作量(不涉及通信)增加了一倍;由于网络保持不变,二分带宽也保持不变,所以我可以合理地期望我的新机器变得两倍快"。
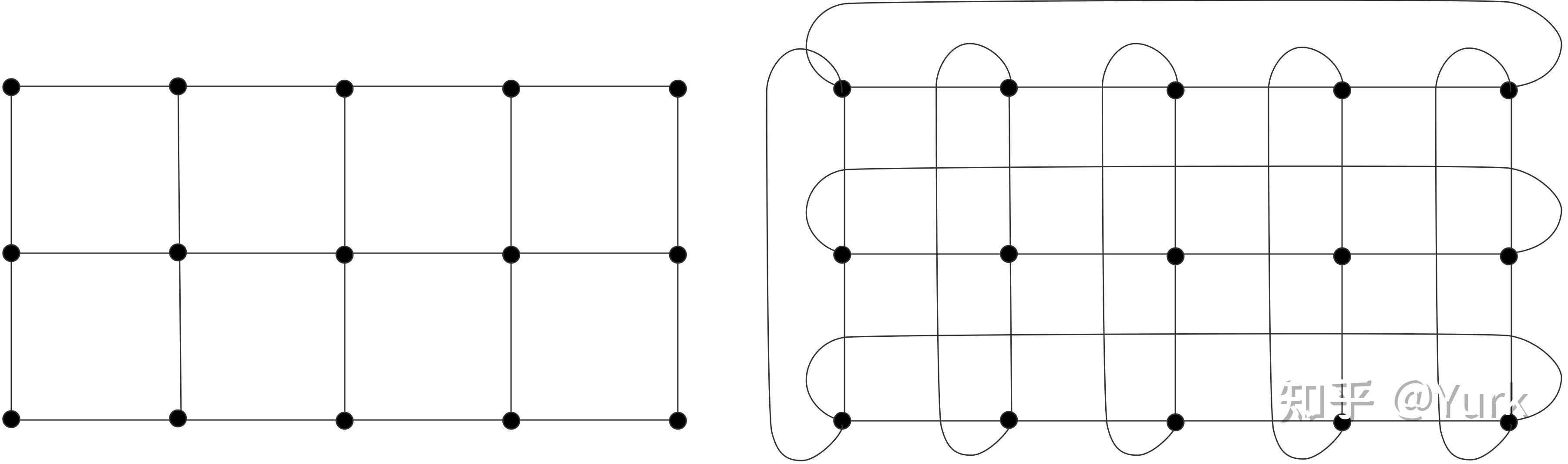
基于网格的设计通常有所谓的环绕或环形连接,它连接二维网格的左右两边,以及顶部和底部。这在图2.19中有所说明。
一些计算机设计声称是高维度的网格,例如5D,但这里并不是所有的维度都是平等的。例如,一个3D网格,其中每个节点是一个四插槽四核,可以被认为是一个5D网格。然而,最后两个维度是完全相连的。
上面我们根据近邻通信的普遍性,对网状组织处理器的适用性做了一个挥手的论证。然而,有时会发生在随机处理器之间的发送和接收。这方面的一个例子就是上面提到的广播。由于这个原因,它希望有一个比网状网络直径小的网络。另一方面,我们希望避免全连接网络的复杂设计。
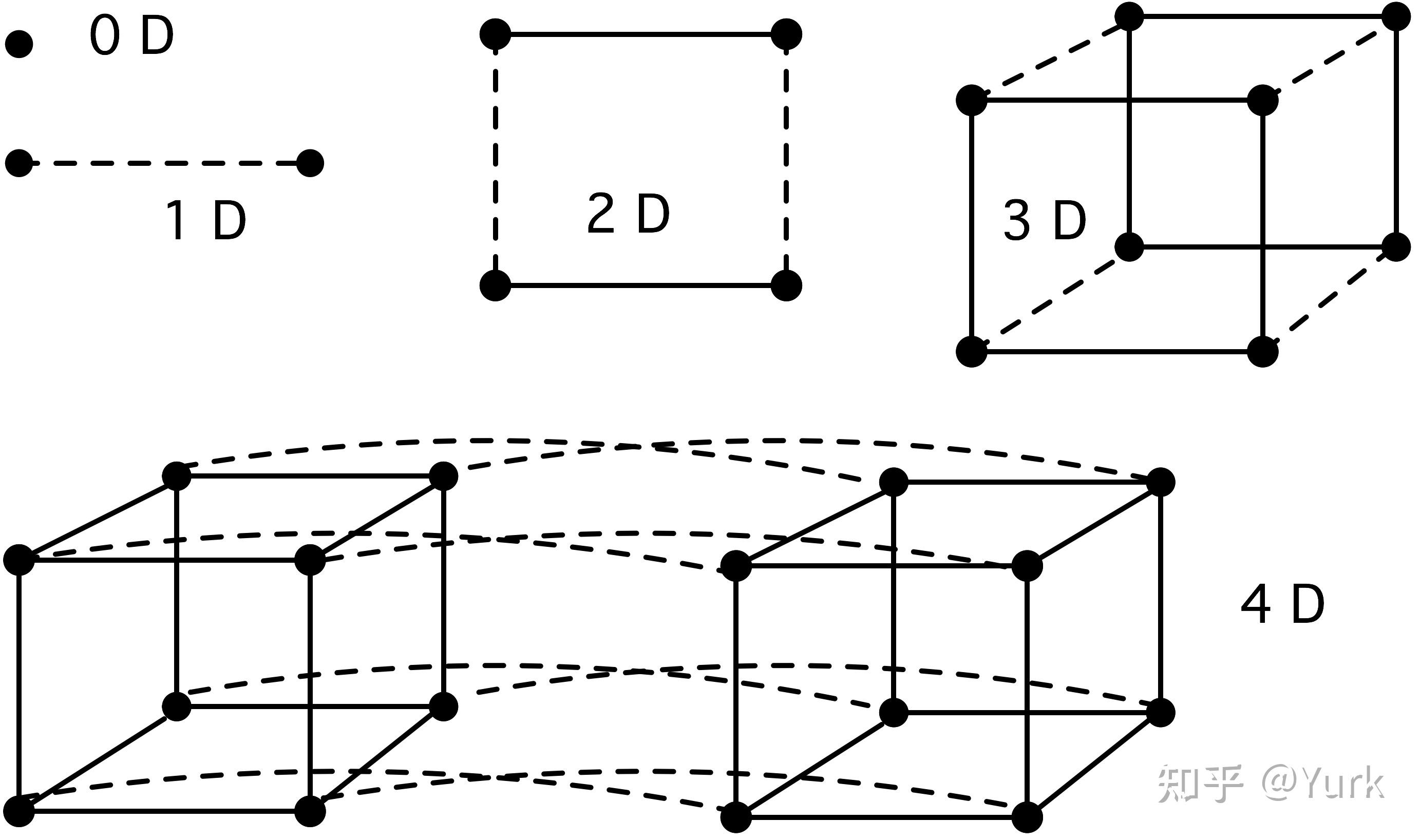
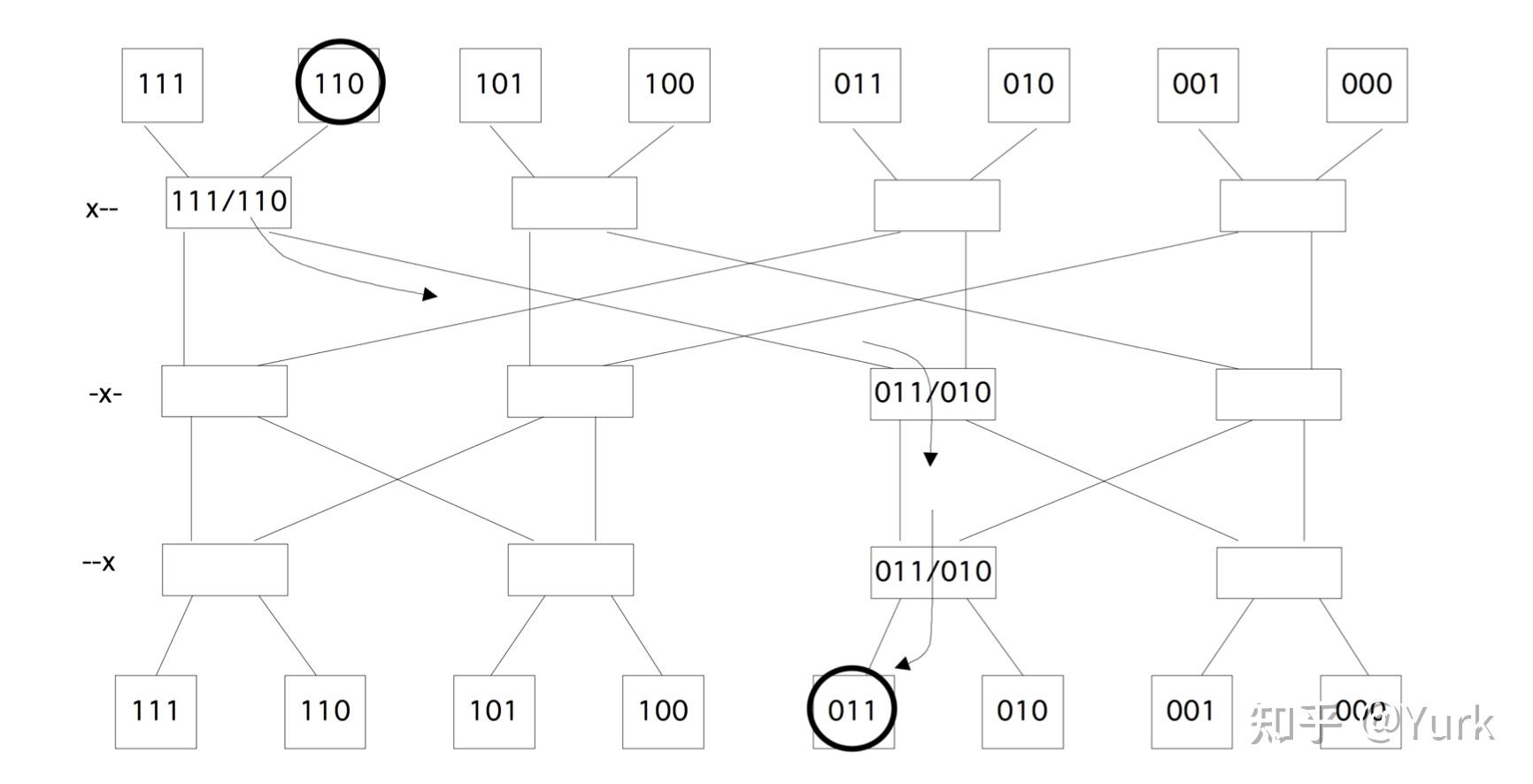
一种可行的解决方案是「超立方体」(hypercube)设计。一个 维的超立方体计算机有
个处理器,每个处理器在每个维度上都与另一个处理器相连;见图2.21。
一个简单的描述方法是给每个处理器一个由 位组成的地址:我们给超立方体的每个节点一个数字,这个数字是描述它在立方体中的位置的比特模式;见图 2.20。
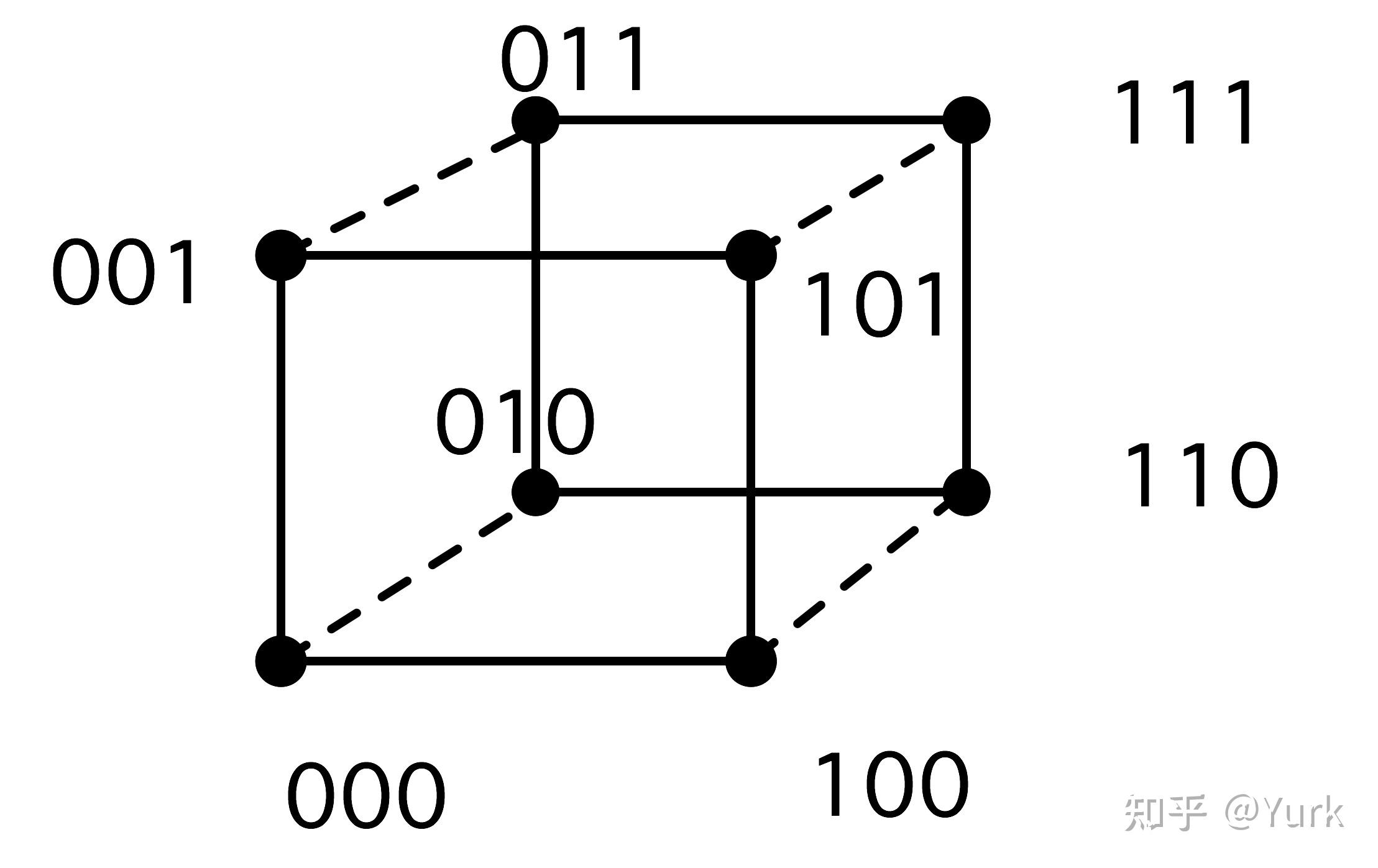
有了这个编号方案,一个处理器就会与其他所有地址正好相差一位的处理器连接起来。这意味着,与网格不同的是,一个处理器的邻居的号码并不是相差1或 ,而是相差1,2,4,8,....。
超立方体设计的最大优点是直径小,通过网络的流量容量大。
练习2.35 超立方体的直径是多少?二分宽度是多少?
该方案的一个缺点是,处理器的设计取决于机器的总尺寸。在实践中,处理器会被设计成可能的最大连接数,而购买较小机器的人就会为未使用的容量买单。另一个缺点是,扩展一台给定的机器只能通过加倍来实现: 以外的其他尺寸是不可能的。
练习2.36 考虑第2.1节中的并行求和例子,并给出在超立方体上并行实现的执行时间。证明在超立方体上的执行可以达到该例子的理论速度(最多一个系数)。在超立方体中嵌入网格上面我们提出了一个论点,即网格连接的处理器是许多物理现象建模应用的合理选择。超立方体看起来不像网格,但它们有足够的连接,可以通过忽略某些连接来简单地假装成网格。
比方说,我们想要一个一维数组的结构:我们想要有编号的处理器,这样处理器 可以直接向 和
发送数据。我们不能像图2.20中那样使用明显的节点编号。例如,节点1与节点0直接相连,但与节点2的距离为2。节点3在一个环中的右邻,节点4,甚至在这个超立方体中的最大距离为3。显然,我们需要以某种方式对节点重新编号。
我们将展示的是,有可能在超立方体中行走,精确地触摸每个角落,这相当于在超立方体中嵌入一个一维网格。

这里的基本概念是一个(二进制反映的)「格雷编码」(Gray code)[87]。这是一种将二进制数 排序为
的方法,即
和
只相差一个比特。显然,普通的二进制数并不满足这一点:1和2的二进制表示已经有两个比特的差异。为什么格雷编码能帮助我们?因为
和
只相差一位,这意味着它们是超立方体中直接相连的节点数。
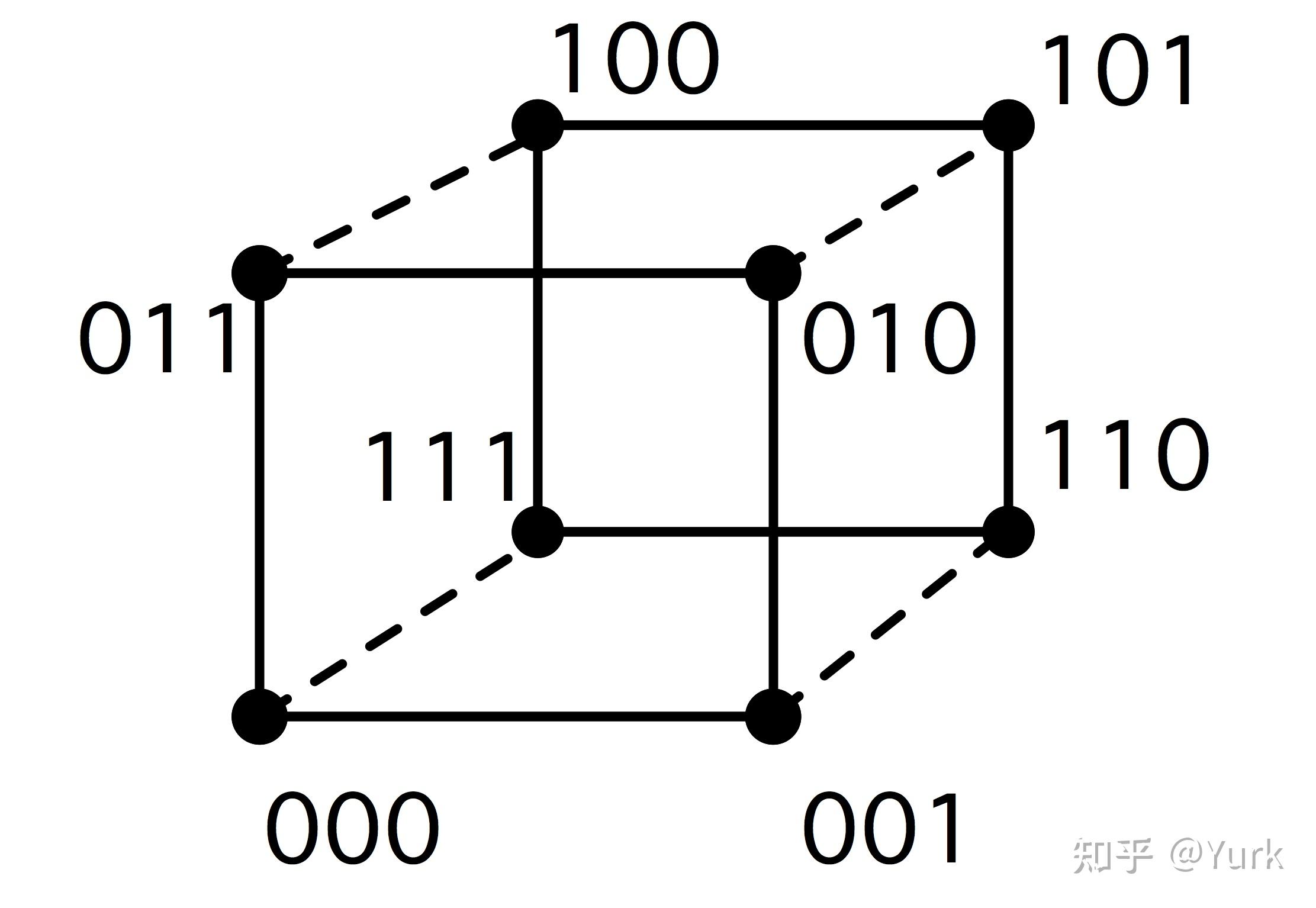
图2.22说明了如何构建一个格雷编码。这个过程是递归的,可以正式描述为 "将立方体分为两个子立方体,对一个子立方体进行编号,交叉到另一个子立方体,并按照第一个子立方体的相反顺序对其节点进行编号"。二维立方体的结果如图2.23所示。
由于格雷编码为我们提供了一种将一维 "网状 "嵌入超立方体的方法,我们现在可以继续往上做。
练习2.37 显示如何将一个 节点的正方形网格嵌入到一个超立方体中,方法是将两个
节点的立方体嵌入的比特模式相加。你如何容纳一个
节点的网格?一个由
个节点组成的三维网格?
上面我们简要地讨论了完全连接的处理器。然而,通过在所有处理器之间制作大量的总线来进行连接是不切实际的。然而,还有另一种可能性,即通过将所有处理器连接到一个「交换机」(switch)或「交换机网络」(switch network)。一些流行的网络设计是「交叉开关」(Cross bar)、「蝶形交换」(butterfly exchange)和「胖树」(fat tree.)。
交换机网络是由交换元件组成的,每个交换元件都有少量(最多十几个)的入站和出站链接。通过将所有的处理器连接到一些交换元件上,并有多个交换阶段,那么就有可能通过网络的路径连接任何两个处理器。
最简单的开关网络是一个交叉开关,由 水平线和垂直线组成,每个交叉点上都有一个开关元件,决定这些线是否连接在一起;见图2.24。如果我们把横线指定为输入,竖线指定为输出,这显然是让
输入映射到
输出的一种方式。每一个输入和输出的组合(有时称为 "排列组合")都是允许的。
这种类型的网络的一个优点是,没有任何连接可以阻挡另一个连接。主要的缺点是开关元素的数量是 ,是处理器数量
的一个快速增长的函数。
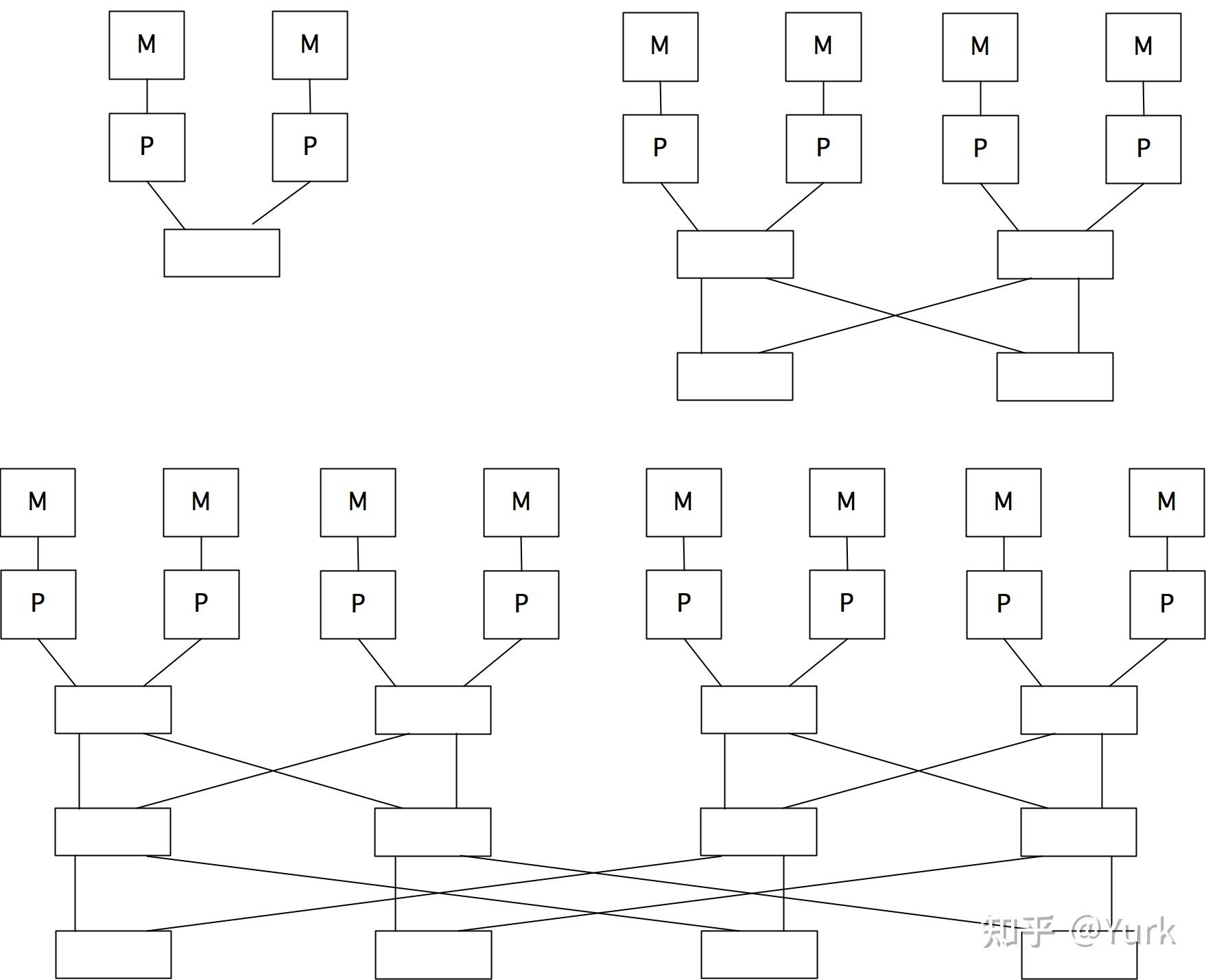
蝶形交换网络是由小型交换元件构成的,它们有多个阶段:随着处理器数量的增加,阶段的数量也随之增加。图2.25显示了连接2、4和8个处理器的蝶形网络,每个处理器有一个本地存储器。(另外,你可以把所有的处理器放在网络的一边,而把所有的存储器放在另一边)。
正如在图2.26中所示,蝶形交换允许几个处理器模拟访问内存。而且,它们的访问时间是相同的,所以交换网络是实现UMA结构的一种方式;见2.4.1节。有一台基于Butterfly交换网络的计算机是BBN Butterfly(http://en.wikipedia.org/wiki/BBN_Butterfly)。在2.7.7.1节中,我们将看到这些想法是如何在一个实际的集群中实现的。
练习 2.38 对于简单的交叉开关和蝶形交换,随着处理器数量的增加网络需要扩展。给出两种情况下连接 处理器和存储器所需的导线数量(某种单位长度)和交换元件的数量。一个数据包从存储器到处理器所需的时间,用穿越单位长度的导线和穿越开关元件的时间表示是多少?
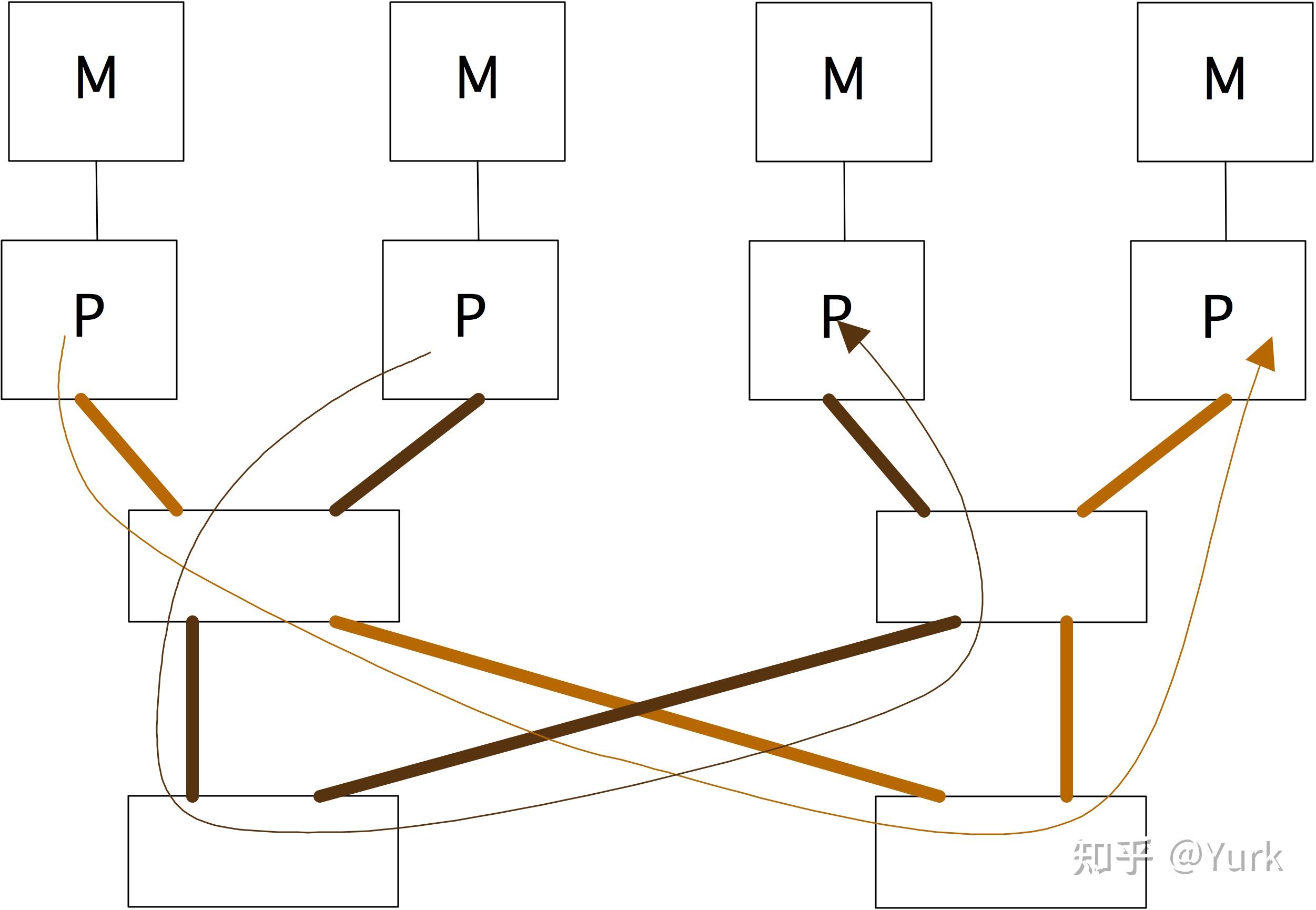
通过蝶形交换网络的数据包路由是基于考虑目的地地址的位数来完成的。在第 层,考虑第
个数字;如果是1,则选择开关的左出口,如果是0,则选择右出口。这在图2.27中有所说明。如果我们把存储器连接到处理器上,如图2.26所示,我们只需要两个比特(到最后一个开关),但还需要三个比特来描述反向路线。
如果我们像树一样连接交换节点,那么在靠近根部的地方就会出现很大的拥堵问题,因为只有两根线连接到根注。假设我们有一棵 级树,所以有
个叶子节点。如果左边子树上的所有叶子节点都试图与右边子树上的节点通信,我们就有
条信息通过一条线进入根部,同样也通过一条线出去。胖树是一个树状网络,每一级都有相同的总带宽,这样就不会出现这种拥堵问题:根部实际上会有
条进线和出线连接[88]。图2.28在左边显示了这种结构;右边显示了Stampede集群的一个机柜,机柜的上半部和下半部有一个叶子开关。
第一个成功的基于胖树的计算机结构是连接机CM5。
在胖树中,就像在其他交换网络中一样,每个信息都带有自己的路由信息。由于在胖树中,选择仅限于上升一级,或者切换到当前级别的其他子树上,因此一条信息需要携带的路由信息的位数与级别相同,对于 处理器来说是
。
练习 2.39 证明胖子树的分叉宽度是 ,其中
是亲子叶子节点的数量。提示:说明只有一种方法可以将胖树连接的处理器集合分割成两个连接的子集。
[142]中对胖树的理论阐述表明,胖树在某种意义上是最优的:它可以像任何其他需要相同空间来构建的网络一样快速传递信息(最多对数因素)。这个说法的基本假设是,离根更近的开关必须连接更多的线,因此需要更多的组件,相应地也就更大。这个论点虽然在理论上很有趣,但没有实际意义,因为网络的物理尺寸在目前最大的使用胖树互连的计算机中几乎没有起到作用。例如,在德克萨斯大学奥斯汀分校的TACC Frontera集群中,只有6个核心交换机(即容纳胖树最高层的机柜),连接91个处理器机柜。
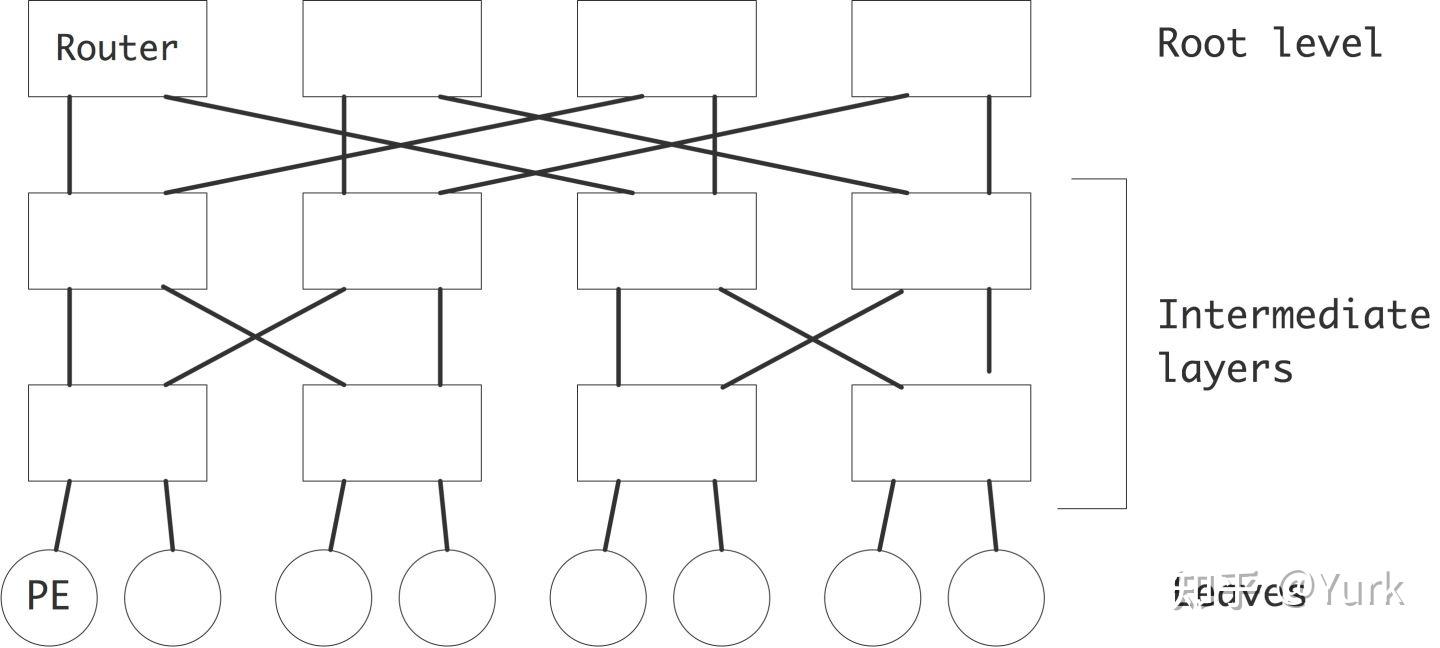
如上图所示,胖树的建设成本很高,因为每下一级都必须设计一个新的、更大的交换机。因此,在实践中,一个具有胖子树特征的网络是由简单的开关元件构成的;见图2.29。这个网络的带宽和路由可能性与胖树相当。路由算法会稍微复杂一些:在胖树中,一个数据包只能以一种方式上升,但在这里,一个数据包必须知道要路由到两个较高的交换机中的哪个。
这种类型的交换网络是Clos网络的一种情况[34]。
在实践中,胖树网络不使用2进2出的元件,而是使用20进20出的开关。这使得网络中的层数有可能被限制在3或4个。(顶层交换机被称为脊柱卡)。
在这种情况下,网络分析的一个额外的复杂因素是超额订购的可能性。网卡中的端口可以配置为输入或输出,而只有总数是固定的。因此,一个40端口的交换机可以被配置为20进20出,或者21进19出,等等。当然,如果所有连接到交换机的21个节点同时发送,19个出端口将限制带宽。
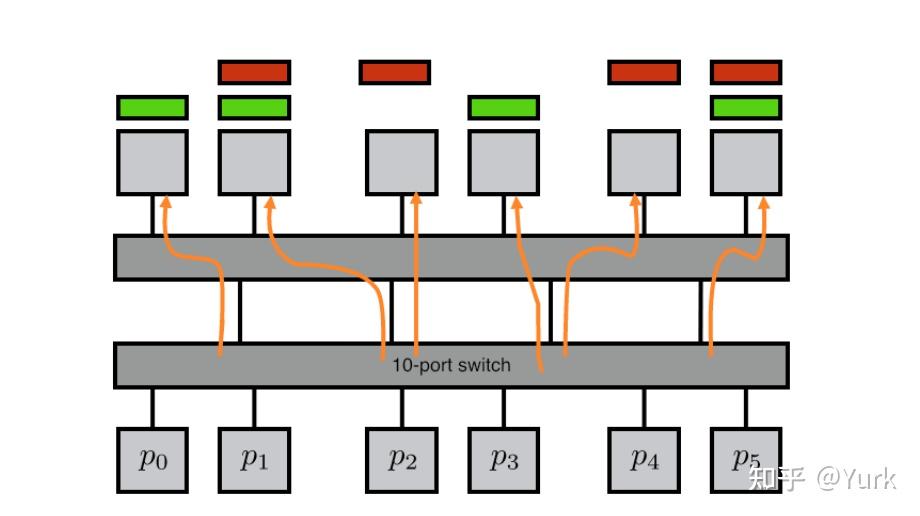
还有一个问题。让我们考虑建立一个小型集群,交换机配置为有 入端口和
出端口,这意味着我们有
端口交换机。图2.30描述了两个这样的开关,总共连接了
个节点。如果一个节点通过交换机发送数据,它对
条可用导线的选择由目标节点决定。这就是所谓的输出路由。
显然,我们只能期望 个节点能够在有信息碰撞的情况下进行发送,因为这就是交换机之间可用导线的数量。然而,对于许多
目标的选择,无论如何都会有对导线的争夺。这就是生日悖论的一个例子。
练习 2.40 考虑上述架构, 个节点通过切换间的
线发送。编一个模拟代码,其中
个节点中的
向一个随机选择的目标节点发送一个信息。作为
的函数,碰撞的概率是多少?找到一种方法来制表或绘制数据。
作为反馈,请给出简单情况下 的统计分析。

上面的讨论有些抽象,但在现实生活中的集群中,你可以实际看到网络设计的体现。例如,肥大的树形集群网络会有一个中央机柜,对应树形中的最高层。图2.31显示了TACC Ranger(已不再使用)和Stampede集群的交换机。在第二张图片中可以看出,实际上有多个冗余的胖树网络。
另一方面,像IBM BlueGene这样基于环状网络的集群,看起来将是一个相同机柜的集合,因为每个机柜都包含网络的一个相同部分;见图2.32。
作为实践中联网的一个例子,让我们考虑一下德克萨斯高级计算机中心的Stampede集群,它是一个多根多级的胖树。
- 每个机架由2个机箱组成,每个机箱有20个节点。
- 每个机箱都有一个叶子开关,它是一个内部的横杆,使机箱中的节点之间有完美的连接性。
- 叶子交换机有36个端口,其中20个连接到节点,16个向外。这种超额订阅意味着最多只有16个节点在机箱外通信时可以拥有完美的带宽。
- 有8个中心交换机,作为8个独立的胖树根发挥作用。每个机箱通过两个连接到每个中央交换机的 "叶卡",正好占用了16个出站端口。
- 每个中心交换机有18个针卡,每个针卡有36个端口,每个端口连接到不同的叶卡。
- 每台中央交换机有36个叶卡,18个端口连接到叶子交换机,18个端口连接到脊柱卡。这意味着我们可以支持648个机箱,其中640个被实际使用。
网络中的一个优化是,与同一叶卡的两个连接进行通信,没有较高树级的延迟。这意味着,一个机箱中的16个节点和另一个机箱中的16个节点可以有完美的连接。
然而,对于静态路由,如Infiniband中使用的路由,有一个与每个目的地相关的固定端口。(目的地到端口的这种映射在每个交换机的路由表中)。 因此,对于20个可能的目的地中的16个节点的某些子集,将有完美的带宽,但其他子集将看到两个目的地的流量通过同一个端口。
Cray的蜻蜓网络是一个有趣的实际妥协。上面我们说过,一个完全连接的网络将太过昂贵,无法扩大规模。然而,如果数量保持有限的话,拥有一个完全连接的处理器集合是可能的。蜻蜓设计使用小的完全连接的组,然后将这些组组成一个完全连接的图。
这引入了一个明显的不对称性,因为一个组内的处理器拥有更大的带宽,而组与组之间则没有。然而,由于动态路由,信息可以采取非最小路径,通过其他组进行路由。这可以缓解争夺问题。


上面所说的发送信息可以被认为是一个单位时间的操作,当然是不现实的。一个大的信息比一个短的信息需要更长的时间来传输。有两个概念可以对传输过程进行更现实的描述;我们已经看到了在处理器的缓存层之间传输数据的情况。
- 延迟 在两个处理器之间建立通信需要花费大量时间,这与信息大小无关。这所花费的时间被称为信息的延时。造成这种延迟的原因有很多。
- 两个处理器进行 "握手",以确保收件人已经准备好,并且有适当的缓冲空间来接收信息。
- 信息需要由发送方进行编码传输,并由接收方进行解码。
- 实际传输可能需要时间:并行计算机通常足够大,即使在光速下,信息的第一个字节也需要数百个周期来穿越两个处理器之间的距离。
- 带宽 在两个处理器之间的传输开始后,主要的数字是每秒可通过通道的字节数。这就是所谓的带宽。带宽通常可由信道速率(物理链路可传送比特的速率)和信道宽度(链路中物理线的数量)决定。信道宽度通常是16的倍数,通常为64或128。这也可以表示为,一个通道可以同时发送一个或两个8字节的字。

带宽和延迟被正式定义为
为一个 字节的信息的传输时间。这里,
是延迟,
是每字节的时间,也就是带宽的倒数。有时我们会考虑涉及通信的数据传输,例如在集体操作的情况下。然后我们将传输时间公式扩展为
其中 是每次操作的时间,也就是计算率的倒数。
也可以将这个公式细化为
其中 是所穿越的网络 "「跳」(hops)"。然而,在大多数网络中,
的值远远低于
的值,所以我们在这里将忽略它。另外,在胖树网络中,跳数是
的数量级,其中
是处理器的总数,所以它无论如何都不可能很大。
在前面我们发现了关于单处理器计算中的位置性概念的讨论。并行计算中的位置性概念包括所有这些以及更多的层次。
- 核心之间:私有缓存 现代处理器上的核心有私有相干缓存。这意味着你似乎不必担心位置性问题,因为无论数据在哪个缓存中都可以访问。然而,维持一致性需要花费带宽,所以最好是保持访问的本地化。
- 内核之间:共享高速缓存 内核之间共享的高速缓存是一个不需要担心位置性的地方:这是处理核心之间真正对称的内存。
- 在插槽之间:节点(或主板)上的插槽在程序员看来是共享内存的,但这实际上是NUMA访问,因为内存与特定的插槽相关。
- 通过网络结构:有些网络有明显的位置效应。你在第2.7.1节中看到了一个简单的例子,一般来说,很明显,任何网格型网络都会有利于 "附近 "处理器之间的通信。基于胖树的网络似乎不存在这样的争论问题,但是层次引起了不同形式的定位性。比节点上的局域性高一级,小群的节点通常由一个叶子开关连接,它可以防止数据进入中央开关。
本文翻自高性能计算导论:《Introduction to High Performance Scientific Computing》-Victor Eijkhout,已获得原作者授权,原文地址:Bitbucket

